Information Retrieval Labor, LLMs, and the Semantic Web
I have a hunch that one of the more useful applications of LLMs in the longer term will be transforming unstructured prose into structured data with the guidance of a schema. By "schema" I mean a formal syntactic structure (e.g. a JSON Schema, TypeScript type) chosen by a human being with a particular set of retrieval tasks in mind.
For a very cool example of what this approach can yield, check out Théophile Cantelobre's visualization of the connections between people in the culinary world and the restaurants they've been involved in, generated by means of data extracted from restaurant reviews.
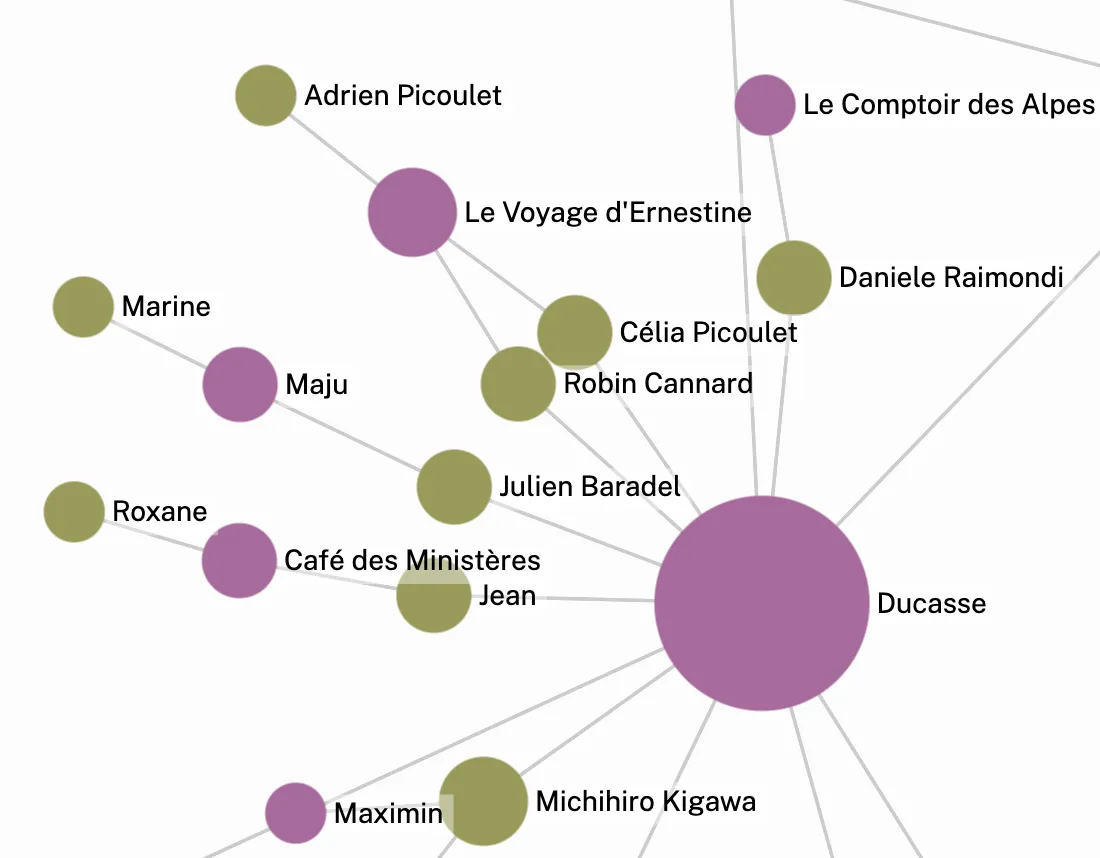
There are some really interesting libraries being developed, like instruct-js, that handle the plumbing required to prompt LLMs with a schema that can be realized as a static type for the programming language and ensure at run time that the results conform to that schema.
In hindsight, it seems clear that one major reason the "semantic web" failed to catch on was that it wholly neglected the cost of the labor required to develop machine-readable formats and recast existing information in those formats. If LLMs can bring that cost down a bit, commensurate portion of the semantic web vision might yet be realized. It will hardly be world-transforming, but perhaps it will marginally improve the lives of some researchers and librarians working in well-defined fields.
Even such humble visions require a lot of work. Julian Warner's historically-informed theory of information retrieval suggests that there is no free lunch to be had through machine-augmentation: holding "search power" fixed, labor can only be shifted from the "description" to the "search" phase of retrieval. I believe the fullest statement of his theory remains Human Information Retrieval (2009).